7. Bestimmung der Prüfverteilung
Die Prüfverteilung zeigt, wie die Prüfgrösse unter der Annahme der Gültigkeit der Arbeitshypothese H0, d.h. bei einer identischen
zentralen Tendenz in den Populationen verteilt ist.
Die grundlegende Idee zur Bestimmung der Prüfverteilung lässt sich an einem einfachen Gedankenexperiment über 7 Schritte verdeutlichen.
Alternativ zum Text können Sie die Punkte 1-5 auch als Animation ansehen und bei Punkt 6 weiterfahren.
- Ausgangspunkt sind 2 Populationen, in denen ein ordinal skaliertes Merkmal in identischer Weise verteilt ist. Das Merkmal
hat damit in beiden Populationen sicher eine identische zentrale Tendenz. Die Daten werden als Kugeln dargestellt, wobei Daten
mit gleichem Ausprägungsgrad in gleiche Gefässe eingeordnet werden.
Daten der beiden Populationen (Klicken auf die Box schliesst diese wieder.)
- Werden die Kugeln pro Ausprägungskategorie ausgezählt, so erhalten wir die Häufigkeitsverteilungen.
Häufigkeitsverteilungen (Klicken auf die Box schliesst diese wieder.)
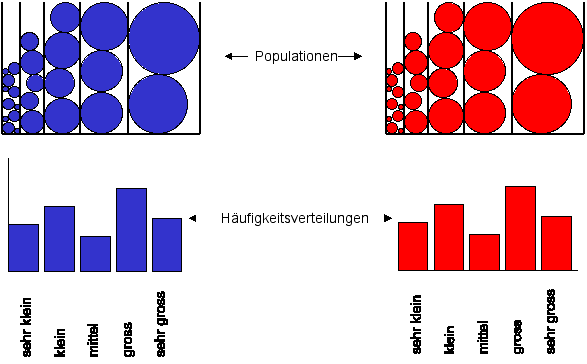
- Aus den beiden Populationen wird nun je eine Zufallsstichprobe gezogen, aus der einen Population eine Stichprobe von 3 Elementen,
aus der anderen eine Stichprobe von 2 Elementen. Die Ausprägungsgrade der zufällig gezogenen Elemente werden in einer Tabelle
zusammengetragen.
Daten der beiden Zufallsstichproben (Klicken auf die Box schliesst diese wieder.)
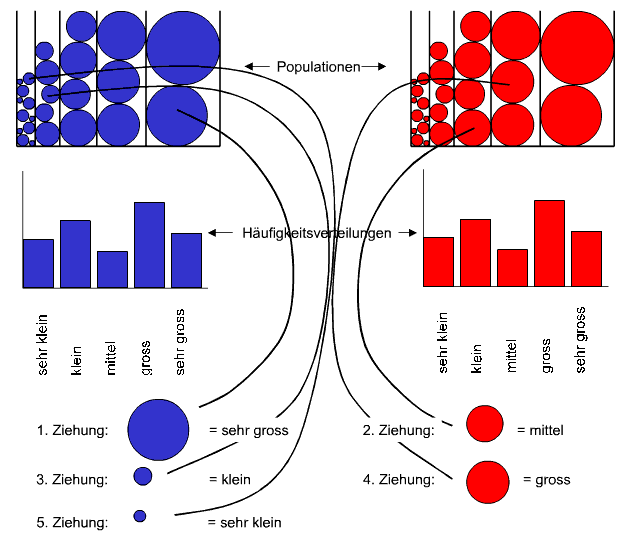
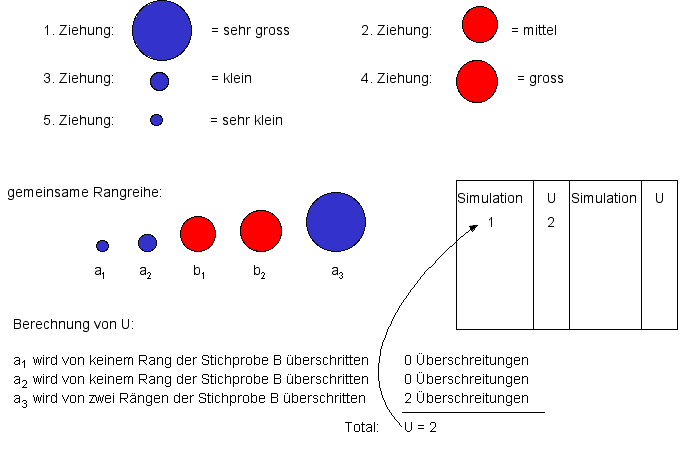
Nun bringen wir die Kugeln gemäss ihren Ausprägungsgraden in eine gemeinsame Rangreihe.Gemeinsame Rangreihe der Stichprobendaten (Klicken auf die Box schliesst diese wieder.)
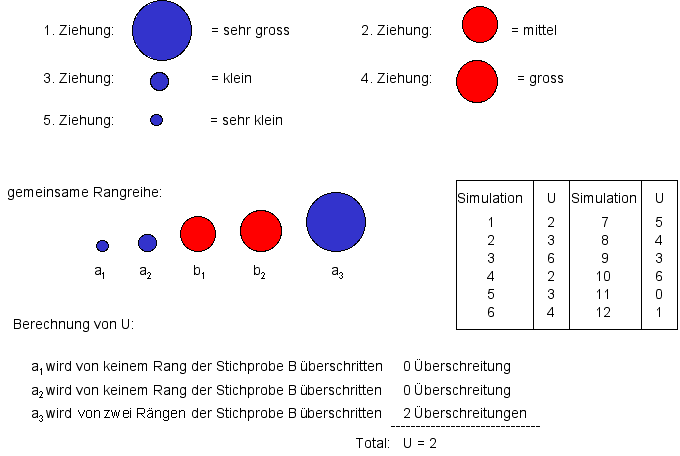
Anhand dieser gemeinsamen Rangreihe bestimmen wir die Rangplatzüberschreitungen U und notieren den Ausprägungsgrad von U in einer Tabelle.Berechnung von U (Klicken auf die Box schliesst diese wieder.)
- Wir legen alle Kugeln in die Gefässe zurück aus denen sie entnommen wurden, und wiederholen Schritt 3, d.h. wir ziehen wiederum
zwei Zufallsstichproben.
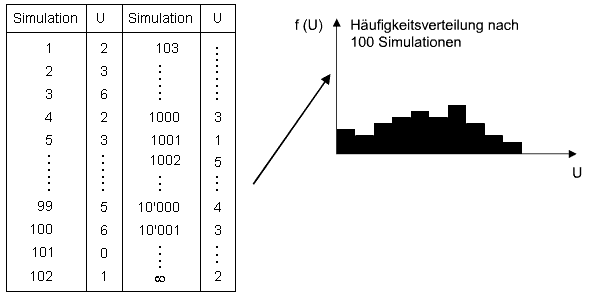
- Spielt man die Simulation mehrmals (theoretisch unendlich oft) durch und berechnet jedesmal U, so füllt sich unsere Tabelle
mit den Ausprägungsgraden von U.
Tabelle der ermittelten Ausprägungen von U nach 12 Simulationen (Klicken auf die Box schliesst diese wieder.)
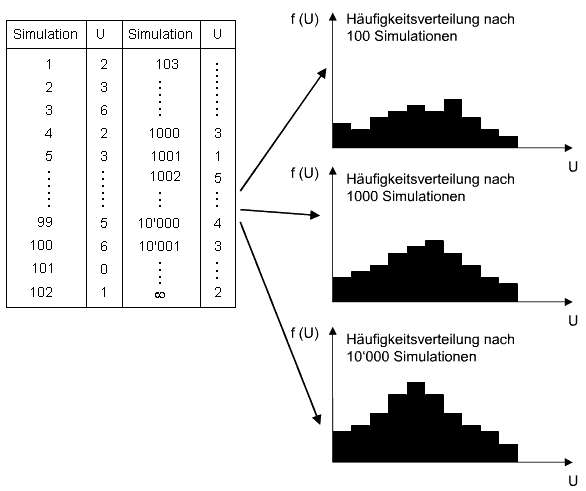
- Die Daten unserer Tabelle können als Häufigkeitsverteilung dargestellt werden, wobei sich diese Häufigkeitsverteilung mit
der Zahl der Simulationsdurchgänge verändert.
Häufigkeitsverteilung von U nach 100 Simulationen (Klicken auf die Box schliesst diese wieder.)
Häufigkeitsverteilung von U nach 1000 resp. 10000 Simulationen (Klicken auf die Box schliesst diese wieder.)
- Dem aufmerksamen Beobachter wird kaum entgangen sein, dass bei einer sehr grossen Zahl von Simulationen die Ausprägungsgrade
von U eingipflig und symmetrisch verteilt sind.
Die Statistiker nennen diese Verteilung eine U-Verteilung. Freundlicherweise haben sie für uns auch die Verteilungsparameter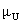 und
und 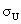 bestimmt:
bestimmt: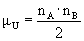
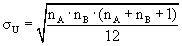
Bei grösseren Stichproben, d.h. wenn mindestens eine der zu vergleichenden Stichproben mehr als 10 Elemente umfasst, geht die U-Verteilung über in eine Normalverteilung N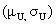
Die Prüfverteilung für grössere Stichproben (Klicken auf die Box schliesst diese wieder.)

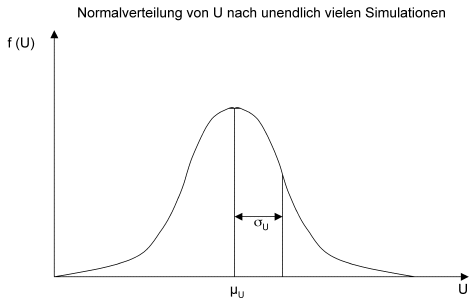
Damit haben wir unser Ziel erreicht! Wir wissen, wie die Prüfgrösse U resp. U' verteilt ist, wenn die beiden Stichproben aus
Populationen stammen, in denen das Merkmal dieselbe zentrale Tendenz aufweist.
Liegt nun von einem Stichprobenvergleich ein konkreter Ausprägungsgrad von U resp. U' vor, so können wir anhand der Prüfverteilung
entscheiden, mit welcher Wahrscheinlichkeit dieser Ausprägungsgrad rein zufällig auftreten könnte, wenn die beiden Stichproben
aus Populationen mit identischer zentraler Tendenz stammen würden.
Diese Beurteilung eines konkreten Ausprägungsgrades der Prüfgrösse anhand der Prüfverteilung wollen wir im Rahmen unseres
Beispiels kurz besprechen.
FAQ (Klicken auf die Box schliesst diese wieder.)
